




2011-2017 © МБУЗ ГКП № 7, г.Челябинск.
СпециалистыЦеныПоказания к УЗИ брахиоцефальных артерий (БЦА)Дуплексное сканирование брахиоцефальных артерий (БЦА)Почему у нас
| Дуплексное сканирование брахиоцефальных артерий | 1500 ₽ |
Дуплексное сканирование брахиоцефальных артерий – метод ультразвуковой диагностики магистральных кровеносных сосудов на шее, отвечающих за кровоснабжение головного мозга. Во время исследования визуализируются общие, наружные, внутренние сонные и позвоночные артерии, а также исследуется гемодинамика посредством цветового допплеровского сканирования.
• Основное показание диагностика проходимости сонных артерий, как основного риска инсульта. Раннее обнаружение стенозов сонных артерий поможет вашим докторам предупредить инсульт;
• Наличие факторов риска развития инсульта: артериальная гипертензия, сахарный диабет, высокий уровень холестерина, гиперлипидемия, неблагоприятная наследственность, перенесенные транзиторные ишемические атаки;
• Оценка состояния сонных артерий после операций каротидной эндартериэктомии и стентирования сонных артерий;
• Предстоящая операция на сердце;
• Прочие симптомы, свидетельствующие о изменении кровотока по артериям шеи (головные боли, разное артериальное давление на верхних конечностях, опухолевидные образования на шее).
Он позволяет видеть состояние крупных артерий, периферических сосудов и мелких подкожных капилляров, а также распределение крови в просвете русла. Заметно любое патологическое отклонение от нормы.
Зрительная оценка имеющихся изменений внутри просвета кровеносного сосуда позволяет диагностировать заболевание на раннем этапе.
1. Все УЗИ-исследования проводятся на современном оборудовании с определением кровотока в органе и образованиях (с ЦДК-цветным дуплексным сканированием). Например образование(узел или какое-либо уплотнение) , который активно кровоснабжается, требует особого внимания. Все это позволяет точно поставить диагноз и своевременно направить на лечение.
2.Мы предлагаем инновационный консилиумный подход к каждому пациенту.
3.Результаты (УЗИ, осмотра, ЭКГ, Холтер-ЭКГ, СМАД, велоэргометрии, анализов) распечатываются и выдаются сразу в удобной папке пациенту. Кроме того они сохраняются в электронном виде в базе данных (электронная медицинская карта пациента) МЦ «Широких сердец» и позволяют врачу оценить динамику лечения и наблюдения. Так же на нашем сайте есть услуга: Личный кабинет, где все результаты хранятся в электронном виде и могут быть открыты пациентов в любом месте и в любое время самостоятельно. Логин личного кабинета это номер телефона, а пароль высылается посредством смс на указанный телефон после оплаты услуг. При возникновении проблем можно связаться с администраторами центра по телефону.
При возникновении проблем можно связаться с администраторами центра по телефону.
Сосуды головного мозга являются сложно устроенной системой, способной к саморегуляции и поддержанию мозгового кровотока. Поэтому только комплексная диагностика, включающая ультразвуковое сканирование, компьютерную томографию, магнитно-резонансную томографию позволяет своевременно и точно выбрать тактику лечения и оценить его эффективность. При проведении УЗДС оценивается анатомия сосудов, состояние стенки и просвета артерий и одновременно определяются показатели кровотока с использованием режима допплерографии и цветного сканирования, что дает возможность получить более точное представление о состоянии сосудов. С помощью УЗДС диагностируются атеросклеротические бляшки, тромбы в просвете, извитость и расслоение артерий.
Начальным ультразвуковым признаком атеросклероза является не бляшка, а утолщение стенки сонной артерии на доли миллиметра. Этот показатель обязательно определяется при дуплексном сканировании и называется толщина комплекса интима-медиа (КИМ). Он учитывается при оценке эффективности лечения статинами и гипотензивной терапии. Увеличение КИМ более 1.0 мм обычно связано с факторами риска сердечно-сосудистых заболеваний: артериальная гипертензия, сахарный диабет, курение, повышение холестерина в крови и др.
Этот показатель обязательно определяется при дуплексном сканировании и называется толщина комплекса интима-медиа (КИМ). Он учитывается при оценке эффективности лечения статинами и гипотензивной терапии. Увеличение КИМ более 1.0 мм обычно связано с факторами риска сердечно-сосудистых заболеваний: артериальная гипертензия, сахарный диабет, курение, повышение холестерина в крови и др.
При прогрессировании атеросклеротического процесса происходит образование бляшек. Чаще всего бляшки локализуются в каротидной бифуркации – месте деления общей сонной артерии на наружную и внутреннюю. Многочисленные клинические исследования доказали, что наличие бляшки в каротидной бифуркации является значимым фактором риска возникновения инсульта, смерти и инфаркта миокарда. Вот почему важно выявить атеросклеротические изменения артерий на ранних стадиях. В ходе дуплексного сканирования определяется не только локализация бляшки, но и другие ее характеристики, важные для выбора дальнейшей тактики лечения: форма, размер, структура, поверхность и степень сужения (стеноза). Если просвет артерии полностью закрыт, это называется окклюзией.
Если просвет артерии полностью закрыт, это называется окклюзией.
При исследовании брахиоцефальных артерий довольно часто встречается извитость артерий, связанная с их удлинением. Главные причины извитости сонных артерий – повышение артериального давления и атеросклероз. Извитость позвоночных артерий чаще связана с деформацией шейного отдела позвоночника, т.к эти сосуды проходят в канале поперечных отростков позвонков. Если извитость артерии приводит к пережатию просвета, это может вызвать нарушение мозгового кровотока.
Ультразвуковое сканирование, как и другие методы лучевой диагностики (ангиография, КТ и МРТ), применяется при обследовании пациентов с травматическим поражением сосудов, например диссекцией, т.е. расслоением стенки. Расслоение стенки артерии также бывает спонтанным. Основным симптомом при диссекции артерии головы и шеи является сильная головная боль, которая не купируется обычными обезболивающими средствами.
Васкулиты – воспаление соcудистой стенки аутоиммунной или инфекционной природы. Дуплексное сканирование информативно в случае поражений артерий крупного и среднего калибра – сонных, позвоночных или височных артерий.
Дуплексное сканирование информативно в случае поражений артерий крупного и среднего калибра – сонных, позвоночных или височных артерий.
Благодаря своим преимуществам ультразвуковое дуплексное сканирование брахиоцефальных артерий признано во всем мире как один из основных методов диагностики заболеваний сосудов. Ультразвуковая оценка кровообращения головного мозга, нейросонология, является относительно новым и довольно сложным направлением, требующим от специалиста высокого уровня подготовки и клинического опыта.
В Европейском медицинском центре ультразвуковое дуплексное сканирование брахиоцефальных артерий выполняется на самых современных ультразвуковых системах, позволяющих выявлять заболевание на ранних стадиях, архивировать результаты и проводить их сравнительный анализ в динамике. УЗДС БЦА входит в программы кардиологического и неврологического обследования.
* Цены в Прайс-листе указываются в условных единицах (если Сторонами не определено иное, 1 условная единица равна 1 евро), все расчеты по Договору осуществляются в рублевом эквиваленте. Оплата по Договору осуществляется Заказчиком по курсу ЦБ РФ, действующему на день оплаты, если курс ЦБ РФ не превышает внутренний курс Клиники на день оплаты, указанный путем размещения в сети «Интернет», на официальном сайте медицинских центров Клиники, и на информационных стендах в медицинских центрах. Если курс ЦБ РФ превышает внутренний курс Клиники на день оплаты, оплата осуществляется по внутреннему курсу Клиники.
Данные — один из самых мощных инструментов, доступных любому бизнесу или организации, которая хочет не только выжить, но и подняться на вершину в современном конкурентном и сложном мире. Чем больше доступной информации, тем больше открывается возможностей и лучших решений проблем и препятствий.
Однако к этим данным предъявляются некоторые высокие требования, в том числе необходимость организации и легкого доступа к информации. Все данные в мире не помогут бизнесу, если он не сможет получить доступ к данным и превратить их в действенный актив.
Связанное обучение: Учебное пособие по структурам данных и алгоритмам
Эта дилемма подводит нас к ответу на распространенный вопрос — что такое структура данных? В этой статье будут даны определения структур данных, рассмотрены различные типы структур данных, классификация структур данных и способы применения структур данных. Мы даже углубимся в такие понятия, как линейная структура данных и нелинейная структура данных. Мы рассмотрим такие ресурсы, как вопросы для собеседования по структуре данных, идеально подходящие для людей, претендующих на соответствующую должность.
Мы рассмотрим такие ресурсы, как вопросы для собеседования по структуре данных, идеально подходящие для людей, претендующих на соответствующую должность.
Давайте погрузимся прямо в мир структур данных и алгоритмов
Прежде чем определять структуры данных, давайте немного вернемся назад и спросим: «Что такое данные?» Вот краткий ответ: данные — это информация, оптимизированная для обработки и перемещения, факты и цифры, хранящиеся на компьютерах.
Структуры данных — это особый способ организации данных в специализированном формате на компьютере, позволяющий организовать, обрабатывать, хранить и извлекать информацию быстро и эффективно. Они являются средством обработки информации, представления данных для удобства использования.
Каждое приложение, часть программного обеспечения или основа программы состоит из двух компонентов: алгоритмов и данных. Данные — это информация, а алгоритмы — это правила и инструкции, которые превращают данные во что-то полезное для программирования.
Иными словами, запомните эти два простых уравнения:
Связанные данные + Допустимые операции над данными = Структуры данных
Структуры данных + Алгоритмы = Программы
Связанное обучение: что такое алгоритм? Характеристики, типы и как это написать
Связанное обучение: Алгоритм поиска в ширину
Структура данных — это систематический способ организации данных. Характеристики структур данных:
Эта характеристика упорядочивает данные в последовательном порядке, например, в виде массивов, графиков и т. д.
Статические структуры данных имеют фиксированные форматы и размеры вместе с ячейками памяти. Статическая характеристика показывает компиляцию данных.
Фактор времени должен быть очень пунктуальным. Время работы или время выполнения программы должно быть ограничено. Время работы должно быть как можно меньше. Чем меньше время работы, тем точнее прибор.
Время работы должно быть как можно меньше. Чем меньше время работы, тем точнее прибор.
Каждые данные обязательно должны иметь интерфейс. Интерфейс изображает набор структур данных. Структура данных должна быть четко реализована в интерфейсе.
Пространство в устройстве требует тщательного управления. Использование памяти должно использоваться правильно. Пространство должно быть меньше занято, что свидетельствует о правильной работе устройства.
Элементы данных в линейной структуре данных связаны друг с другом в последовательном порядке, при этом каждый элемент связан с элементами перед ним и за ним. Таким образом, один проход может пройти через структуру. Линейные структуры данных состоят из четырех типов. Они:
Линейная структура данных хранит элементы данных в порядке «первым поступил/последним вышел» или «последним пришел/первым вышел». Эти заказы известны как заказы FILO и LIFO соответственно. Используя стек, элемент можно добавлять и удалять одновременно с одного и того же конца. В Python стек можно разработать следующими способами.
Эти заказы известны как заказы FILO и LIFO соответственно. Используя стек, элемент можно добавлять и удалять одновременно с одного и того же конца. В Python стек можно разработать следующими способами.
В стеке термины «Push» и «Pop» используются вместо «вставить» и «удалить».
Это набор похожих типов данных, которые хранятся в непрерывных ячейках памяти. Массивы также используются в Python. Массивы работают по шкале от 0 до (n-1), где «n» обозначает размер массива. Массивы бывают двух типов. Они:
Очередь — это линейная структура данных, которая следует порядку FIFO. FIFO расшифровывается как First In and First Out. Порядок таков, что элементы, которые вставлены первыми, должны быть удалены первыми. Свойства структуры данных Queue:
Свойства структуры данных Queue:
Связанные списки разделяют структуры данных, которые хранятся последовательно. Последний узел структуры данных будет связан с первым узлом следующей структуры данных. Первый элемент любой структуры данных известен как начало списка. Связанный список помогает в распределении памяти, хранит данные во внутренней структуре и т. д. Существует три типа связанных списков. Их:
Структура данных, в которой элементы данных расположены случайным образом. Элементы расположены не последовательно. Элементы данных присутствуют на разных уровнях. В нелинейных структурах данных существуют разные пути для достижения одним элементом другого элемента. Элементы данных в нелинейных структурах данных связаны с одним или несколькими элементами. Существует два типа нелинейных структур данных. Их:
Элементы данных в нелинейных структурах данных связаны с одним или несколькими элементами. Существует два типа нелинейных структур данных. Их:
Древовидные структуры данных полностью отличаются от массивов, стеков, очередей и связанных списков. Древовидные структуры данных являются иерархическими. Структура данных дерева собирает узлы вместе, чтобы изобразить и стимулировать последовательность. Древовидная структура данных не хранит данные последовательно. Он хранит данные на нескольких уровнях. Верхний узел древовидной структуры данных известен как корневой узел. Любой тип данных может храниться в корневом узле. Каждый узел обязательно должен содержать данные. Ветви в древовидной структуре данных называются дочерними.
Различные части древовидной структуры данных:
В структуре данных графа один узел просто соединяется с другим узлом через ребро графа. Структура данных графа, очевидно, использует нелинейные структуры данных, которые не расположены последовательно. Структуры данных графа состоят из ребер и узлов, представленных буквами E и V соответственно. Структуры графических данных не имеют корневых узлов. В нем нет стандартного порядка расположения данных. Каждое дерево также известно как граф с n-1 ребрами, где «n» представляет собой общее количество вершин в графе. На графиках есть различные категории, такие как неориентированные, невзвешенные, направленные и взвешенные.
Структура данных графа, очевидно, использует нелинейные структуры данных, которые не расположены последовательно. Структуры данных графа состоят из ребер и узлов, представленных буквами E и V соответственно. Структуры графических данных не имеют корневых узлов. В нем нет стандартного порядка расположения данных. Каждое дерево также известно как граф с n-1 ребрами, где «n» представляет собой общее количество вершин в графе. На графиках есть различные категории, такие как неориентированные, невзвешенные, направленные и взвешенные.
Различные части графика выглядят следующим образом.
Типы данных являются основными элементами классификации данных. Типы данных используются при передаче информации между программистом и компилятором. Существуют разные типы данных. Они следующие.
Типы данных используются при передаче информации между программистом и компилятором. Существуют разные типы данных. Они следующие.
В компьютерных программах существует три типа данных, таких как числа, текст и логические значения. Boolean — это тип данных, и значение логического значения может быть либо ложным, либо истинным, либо положительным, либо отрицательным. Логический тип данных доказывает, являются ли данные действительными или недействительными. Логические значения имеют два возможных состояния, например True или False. В двоичной системе используются значения 0 и 1. Логические выражения имеют дело с алгеброй, логическими значениями и двоичными переменными.
Целочисленный тип данных хранит как положительные, так и отрицательные числа вместе с нулем. Целочисленный тип данных использует все эти целые числа для обеспечения точности. Все арифметические операции можно эффективно выполнять с помощью целочисленных типов данных. Если значение данных выходит за числовой диапазон целого числа, это означает, что сервер базы данных не может сохранить это значение. Однако целочисленный тип данных занимает четыре (4) байта памяти на значение.
Все арифметические операции можно эффективно выполнять с помощью целочисленных типов данных. Если значение данных выходит за числовой диапазон целого числа, это означает, что сервер базы данных не может сохранить это значение. Однако целочисленный тип данных занимает четыре (4) байта памяти на значение.
Тип данных с плавающей запятой аппроксимирует действительные значения с помощью формулы, чтобы обеспечить компромисс между диапазоном и точностью. Из-за потребности в высокой скорости обработки в системах с очень маленькими и очень большими действительными числами часто используются вычисления с плавающей запятой. Показатель степени в фиксированной базе обычно используется для масштабирования числа и приближения его представления к определенному количеству значащих цифр.
Двоичные слова используются для хранения чисел в цифровой электронике. Строка битов фиксированной длины (1 и 0) представляет собой двоичное слово. Тип данных определяет, как эти 1 и 0 интерпретируются аппаратными элементами и программными процессами. Существует два разных типа данных для двоичных чисел: с фиксированной запятой и с плавающей запятой. Доступны как знаковые, так и беззнаковые форматы данных с фиксированной точкой. Знакового бита нет. Поэтому двоичное слово обычно явно не выражает, является ли значение с фиксированной запятой знаковым или беззнаковым. Напротив, архитектура компьютера неявно определяет знаковую информацию.
Тип данных определяет, как эти 1 и 0 интерпретируются аппаратными элементами и программными процессами. Существует два разных типа данных для двоичных чисел: с фиксированной запятой и с плавающей запятой. Доступны как знаковые, так и беззнаковые форматы данных с фиксированной точкой. Знакового бита нет. Поэтому двоичное слово обычно явно не выражает, является ли значение с фиксированной запятой знаковым или беззнаковым. Напротив, архитектура компьютера неявно определяет знаковую информацию.
Двоичные слова используются для хранения чисел в цифровой электронике. Строка битов фиксированной длины (1 и 0) называется двоичным словом. Тип данных определяет, как эти 1 и 0 интерпретируются аппаратными элементами и программными процессами. Существует два разных типа данных для двоичных чисел: с фиксированной запятой и с плавающей запятой.
Символьная информация хранится в поле фиксированной длины с помощью типа данных CHAR. Данные могут быть строкой букв, целых чисел и других символов, которые поддерживаются кодовым набором локали вашей базы данных, независимо от того, являются ли они однобайтовыми или многобайтовыми символами.
Данные могут быть строкой букв, целых чисел и других символов, которые поддерживаются кодовым набором локали вашей базы данных, независимо от того, являются ли они однобайтовыми или многобайтовыми символами.
Строки фиксированной или переменной длины могут использоваться для хранения символьных данных. Строки переменной длины не расширяются; строки фиксированной длины расширяются вправо с пробелами на выходе.
Динамически выделяемые блоки памяти управляются и сохраняются с помощью указателей. Объекты данных или массивы объектов хранятся в таких альянсах. Куча или свободное хранилище, представляющее собой пространство памяти, предоставляемое большинством структурированных и объектно-ориентированных языков, — это место, где объекты распределяются динамически.
Строковый тип данных состоит из последовательности символов, либо в виде буквальной константы, либо в виде переменной. Последняя может быть либо постоянной по длине, либо позволять своим элементам изменяться (после создания). Структура данных массива байтов (или слов) часто используется для создания строки, которая обычно рассматривается как разновидность данных и содержит последовательность элементов, обычно символов, с использованием какой-либо кодировки символов.
Последняя может быть либо постоянной по длине, либо позволять своим элементам изменяться (после создания). Структура данных массива байтов (или слов) часто используется для создания строки, которая обычно рассматривается как разновидность данных и содержит последовательность элементов, обычно символов, с использованием какой-либо кодировки символов.
Реализация физических представлений абстрактных типов данных использует структуры данных. При создании эффективного программного обеспечения структуры данных являются ключевым компонентом. Они также необходимы для разработки алгоритмов и использования этих алгоритмов в программном обеспечении. Структуры данных используются в различных аспектах, например,
При предоставлении набора атрибутов и соответствующих структур, которые будут использоваться для хранения записей в системе управления базами данных, структуры данных используются для эффективного сохранения данных.
Структуры данных, в том числе связанные списки для выделения памяти, управления файловыми каталогами и деревьями структуры файлов, а также очереди планирования процессов, используются для предоставления ресурсов и функций базовой операционной системы (ОС).
Информация, совместно используемая приложениями, например пакеты TCP/IP, организована с использованием структур данных.
Двоичные деревья поиска, иногда называемые упорядоченными или отсортированными двоичными деревьями, представляют собой структуры данных, предлагающие практические способы сортировки элементов, таких как строки символов, используемые в качестве тегов. Программисты могут управлять объектами, расположенными с заданным приоритетом, используя структуры данных, такие как очереди приоритетов.
Для индексации элементов, например, хранящихся в базе данных, используются еще более сложные структуры данных, такие как B-деревья.
B-деревья, хэш-таблицы и двоичные деревья поиска — это стандартные методы, используемые для создания индексов, которые ускоряют процесс поиска определенного элемента.
Структуры данных используются приложениями для работы с большими данными для распределения и управления хранилищами данных в распределенных хранилищах, обеспечивая производительность и масштабируемость. Чтобы упростить запросы, несколько сред программирования больших данных, таких как Apache Spark, предлагают структуры данных, которые воспроизводят фундаментальную структуру записей базы данных.
Шаги, которые необходимо использовать для выбора структуры данных, приведены ниже.
1) Первым шагом в определении основных операций, которые должны поддерживаться, является анализ проблемы. Вставка элемента данных в структуру данных, удаление элемента данных из структуры данных и поиск определенного элемента данных являются примерами основных операций.
2) Определите ограничения ресурсов для каждой операции и дайте их количественную оценку.
3) Определите, какая структура данных лучше всего соответствует этим требованиям.
Если базовый тип данных атрибута может быть преобразован в один из типов, для которых поддерживается операция, могут выполняться процессы между типами данных, не включенными в таблицу. К данным можно добавлять или вычитать числа. Количество дней, которые нужно добавить или удалить, представлено целыми числами.
Например, поскольку IEG INT8 превращается в IEG DOUBLE и поддерживается добавление IEG DOUBLE и IEG MONEY, возможно добавление IEG INT8 и IEG MONEY.
Вычислительная сложность — это показатель того, сколько времени и памяти (ресурсов) использует конкретный алгоритм при его выполнении. Перед разработкой кода специалисты по информатике могут прогнозировать время выполнения алгоритма и потребности в памяти, используя математические показатели сложности. Для программистов, реализующих и выбирающих алгоритмы для практических приложений, эти прогнозы являются важным руководством.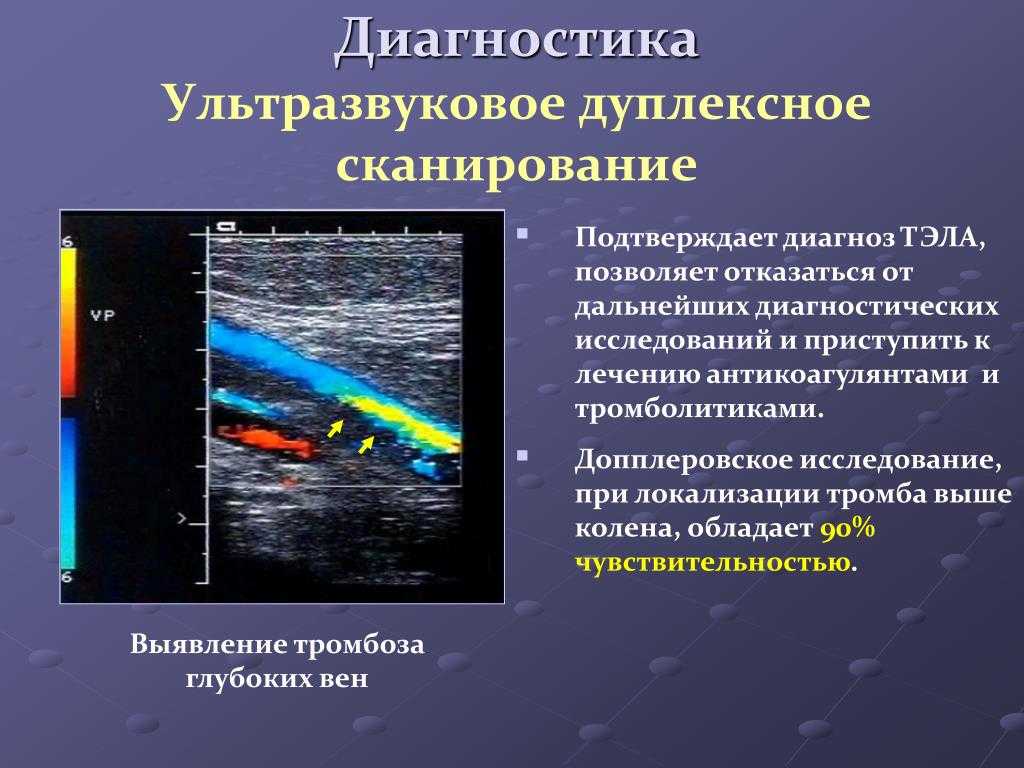
Одной из тех вещей, которые легко распознать, но трудно определить, является элегантная программа. Он эффективно использует слова, не прибегая к запутыванию. Это лаконично, без использования сложного кода. Он обеспечивает баланс между концепциями простоты и ясности, сложностью кода, оставаясь при этом поверхностным для чтения и понимания. Написание кодового эквивалента безупречного письма — конечная цель каждого программиста.
Не существует "волшебного решения" или единственного решения этой проблемы. Стандарты кодирования могут помочь в этом, но они должны быть основаны на прочной основе, которая гарантирует, что суть вопроса доведена до программиста и отражена в коде.
Чтобы ответить на вопрос, что такое структура данных, необходимо понять три основных типа данных.
Абстрактные данные определяются тем, как они себя ведут. Этот тип охватывает графы, очереди, стеки и наборы.
Составные данные содержат комбинированные примитивные типы данных и включают в себя массивы, классы, записи, строки и структуры. Они также могут состоять из других составных типов.
Примитивные данные классифицируются как базовые данные и состоят из логических значений, символов, целых чисел, указателей и чисел с фиксированной и плавающей запятой.
Эти типы данных являются строительными блоками структур данных. Типы данных сообщают интерпретатору или компьютеру, как программист планирует использовать данные. Кроме того, аналитики данных могут выбирать из различных классификаций структур данных. Хитрость заключается в том, чтобы выбрать структуру, наиболее подходящую для ваших нужд и ситуации.
Что такое структура данных? Хороший вопрос! У него так много определений и характеристик, что легко запутаться и перегрузиться терминологией. Как мы только что видели, существуют различные типы и классификации структур данных и самих данных. Такой объем информации вызывает еще больше вопросов. Что такое связанный список? Что такое линейная структура данных? Что такое структура данных???!!
Такой объем информации вызывает еще больше вопросов. Что такое связанный список? Что такое линейная структура данных? Что такое структура данных???!!
Давайте попробуем разобраться в структурах данных, взглянув на классификации. Существует три основных классификации структур данных, каждая из которых состоит из пары характеристик.
Линейные структуры упорядочивают данные в линейной последовательности, например, в массиве, списке или очереди. В нелинейных структурах данные не образуют последовательность, а вместо этого соединяются с двумя или более информационными элементами, например, в виде дерева или графика.
Как следует из самого термина, статические структуры состоят из фиксированных, постоянных структур и размеров во время компиляции. Массив резервирует определенный объем резервной памяти, установленный программистом заранее. Динамические структуры имеют нефиксированные объемы памяти, уменьшающиеся или расширяющиеся в зависимости от требований программы и требований к ее выполнению. Кроме того, расположение связанной памяти может измениться.
Кроме того, расположение связанной памяти может измениться.
Однородные структуры данных состоят из одного и того же типа элементов данных, как наборы элементов в массиве. В неоднородных структурах данные не обязательно должны быть одного типа, например в структурах.
Параметр | Линейная структура данных | Нелинейная структура данных |
| Расположение элементов данных | В случае линейной структуры данных элементы данных хранятся в линейном порядке. Каждый элемент связан с первым и последующим элементами в последовательности. | В случае нелинейной структуры данных элементы данных упорядочиваются нелинейно и присоединяются иерархически. Элементы данных связаны с несколькими элементами. |
| Категории | Линейная структура данных может быть массивом, стеком, связанным списком или очередью. | Нелинейные структуры данных включают деревья и графы. |
| Уровни | Линейная структура данных состоит из одного уровня. В нем нет иерархии. | В этом расположении задействовано несколько уровней. В результате элементы организованы иерархически. |
| Траверс | Поскольку линейные данные имеют только один уровень, для обхода каждого элемента данных требуется только один проход. | Элементы данных нелинейной структуры данных не могут быть извлечены за один проход. Необходимо пройти много перегонов. |
| Использование памяти | В этом случае использование памяти неэффективно. | В этом случае память используется очень эффективно. |
| Приложения | Линейные структуры данных в основном используются при разработке программного обеспечения. | Обработка изображений и искусственный интеллект используют нелинейные структуры данных. |
| Сложность времени | Временная сложность линейной структуры данных растет по мере увеличения размера входных данных. | Временная сложность нелинейной структуры данных часто остается постоянной по мере увеличения размера входных данных. |
| Отношения | Возможна только одна форма связи между фрагментами данных. | Нелинейная структура данных может иметь связь один-к-одному или один-ко-многим между ее частями. |
До сих пор мы касались типов данных и классификаций структур данных. Наш обход множества элементов структур данных продолжится рассмотрением различных типов структур данных.
Массивы представляют собой наборы элементов данных одного типа, хранящихся вместе в соседних ячейках памяти.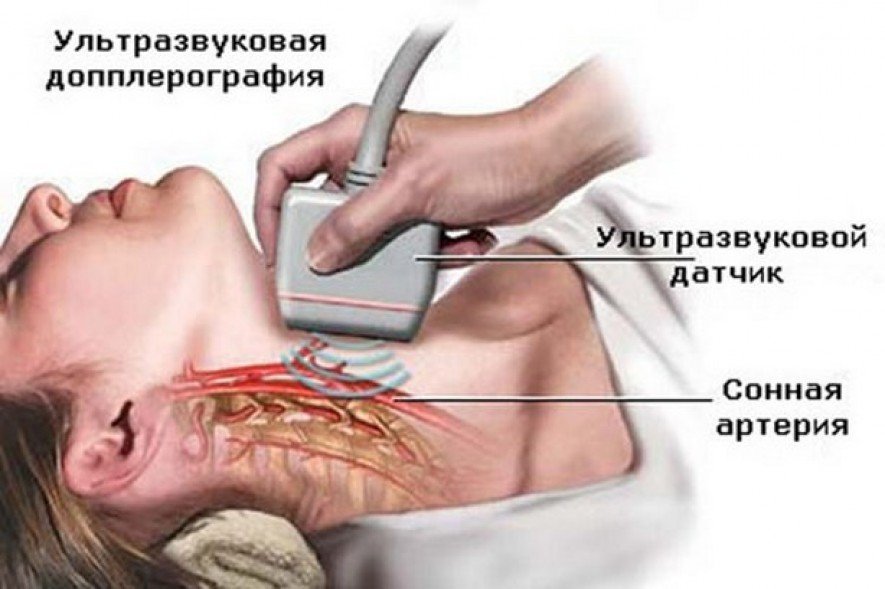 Каждый элемент данных известен как «элемент». Массивы — это самая основная, фундаментальная структура данных. Начинающие специалисты по данным должны освоить построение массивов, прежде чем переходить к другим структурам, таким как очереди или стеки.
Каждый элемент данных известен как «элемент». Массивы — это самая основная, фундаментальная структура данных. Начинающие специалисты по данным должны освоить построение массивов, прежде чем переходить к другим структурам, таким как очереди или стеки.
Графики представляют собой нелинейное графическое представление наборов элементов. Графы состоят из конечных наборов узлов, также называемых вершинами, соединенных связями, поочередно называемыми ребрами. Деревья, упомянутые ниже, представляют собой вариант графа, за исключением того, что последний не имеет правил, определяющих, как соединяются узлы.
Хеш-таблицы, также называемые хэш-картами, могут использоваться как в качестве линейной, так и нелинейной структуры данных, хотя они предпочитают первую. Эта структура обычно строится с использованием массивов. Хэш-таблицы сопоставляют ключи со значениями. Например, каждой книге в библиотеке присвоен уникальный номер, который облегчает поиск информации о книге, например, кто ее проверил, ее текущая доступность и т. д. Книги в библиотеке хешируются до уникального номера.
Например, каждой книге в библиотеке присвоен уникальный номер, который облегчает поиск информации о книге, например, кто ее проверил, ее текущая доступность и т. д. Книги в библиотеке хешируются до уникального номера.
Связанные списки хранят коллекции элементов в линейном порядке. Каждый элемент в связанном списке содержит элемент данных и ссылку или ссылку на последующий элемент в том же списке.
Стеки хранят наборы элементов в линейном порядке и используются при применении операций. Например, порядок может быть «первым пришел, первым вышел» (ФИФО) или «последним пришел, первым ушел» (ЛИФО).
Очереди хранят коллекции элементов последовательно, как стеки, но порядок операций должен быть только "первым пришел, первым вышел". Очереди — это линейные списки.
Читайте также: Реализация очереди с использованием массива

Деревья хранят коллекции элементов в абстрактной иерархии. Это многоуровневые структуры данных, в которых используются узлы. Нижние узлы называются «листовыми узлами», а самый верхний узел известен как «корневой узел». Каждый узел имеет указатели, указывающие на соседние узлы.
Не путать с деревом. Попытки — это структуры данных, в которых хранятся строки, подобные элементам данных, и они размещаются на визуальном графике. Попытки также называются деревьями ключевых слов или деревьями префиксов. Всякий раз, когда вы используете поисковую систему и получаете автопредложения, вы наблюдаете структуру данных trie в действии.
Дерево считается обычным деревом, если его иерархия не ограничена. Количество дочерних узлов, которые может иметь узел в общем дереве, не ограничено. Все остальные деревья являются подмножествами дерева.
Двоичное дерево — это разновидность древовидной структуры данных, в которой каждый родительский узел имеет не более двух дочерних узлов. Как следует из названия, двоичный код означает два, поэтому каждый узел может иметь ноль, один или два узла. Популярность этого дерева выше, чем у большинства других. Двоичное дерево может быть изменено с учетом определенных ограничений и функций, таких как использование дерева AVL, дерева BST, дерева RBT и других. Мы подробно рассмотрим все эти стили по мере продвижения.
Эти древовидные структуры данных нелинейны: один узел соединяется с несколькими другими. К узлу можно присоединить не более двух дочерних узлов. Бинарное дерево поиска названо так потому, что:
Дерево AVL — это самобалансирующееся двоичное дерево поиска. Адельсон-Велши и Лэндис являются изобретателями термина AVL. Здесь впервые были созданы динамически сбалансированные деревья. В зависимости от того, сбалансировано дерево AVL или нет, каждому узлу назначается коэффициент балансировки. Дети узла имеют максимальную высоту одной лозы AVL. Правильные коэффициенты баланса в дереве AVL: 1, 0 и -1. Если к дереву добавляется новый узел, он будет повернут, чтобы обеспечить его сбалансированность. Затем он будет вращаться. В дереве AVL общие операции, такие как просмотр, вставка и удаление, требуют времени O(log n). Обычно он используется при выполнении операций поиска.
Адельсон-Велши и Лэндис являются изобретателями термина AVL. Здесь впервые были созданы динамически сбалансированные деревья. В зависимости от того, сбалансировано дерево AVL или нет, каждому узлу назначается коэффициент балансировки. Дети узла имеют максимальную высоту одной лозы AVL. Правильные коэффициенты баланса в дереве AVL: 1, 0 и -1. Если к дереву добавляется новый узел, он будет повернут, чтобы обеспечить его сбалансированность. Затем он будет вращаться. В дереве AVL общие операции, такие как просмотр, вставка и удаление, требуют времени O(log n). Обычно он используется при выполнении операций поиска.
A B Tree — это более общее бинарное дерево поиска. Дерево m путей со сбалансированной высотой относится к этому типу дерева, где m обозначает порядок дерева. Каждый узел дерева может иметь несколько ключей и более двух дочерних узлов. Листовые узлы бинарного дерева могут находиться на разных уровнях. Важно, чтобы все конечные узлы B-дерева были одинаковой высоты.
Графы нулевого порядка — другое название нулевого графа. Граф с пустым набором ребер называется «нулевым графом». Как следует из названия, нулевой граф имеет 0 ребер и состоит только из изолированных вершин.
Если граф содержит только одну вершину, он называется тривиальным графом. Одна вершина — это все, что нужно для построения тривиального графа, который является наименьшим возможным графом.
Если количество вершин и ребер в графе ограничено, граф называется конечным графом.
Если количество вершин и ребер в графе бесконечно, то граф называется конечным.
Орграфы — это еще один термин для ориентированных графов. Граф называется ориентированным графом или орграфом, если все ребра, соединяющие любые его вершины или узлы, направлены или имеют определенное направление. Под направленными ребрами мы подразумеваем ребра графа, у которых есть направление, указывающее, где они начинаются и где заканчиваются.
Под направленными ребрами мы подразумеваем ребра графа, у которых есть направление, указывающее, где они начинаются и где заканчиваются.
Каждая пара узлов или вершин в простом графе имеет только одно соединяющее их ребро. Как следствие, только одно ребро соединяет две вершины, иллюстрируя взаимно однозначное взаимодействие между двумя компонентами.
Если в графе G=(V,E) есть много ребер, соединяющих две вершины, такой граф называется мультиграфом. Мультиграф не имеет циклов.
Граф считается полным, если это простой граф. Ребра, имеющие n вершин, должны быть связаны. Он также известен как полный граф, поскольку степень каждой вершины должна быть n-1.
Псевдограф — это тот, который имеет петлю в дополнение к другим ребрам.
Регулярный граф — это одна из таких категорий типа графа, которая является простым графом с одинаковым значением степени в каждой из вершин. В результате каждый граф в целом является регулярным графом.
В результате каждый граф в целом является регулярным графом.
Двудольный граф можно разделить на две непустые непересекающиеся части с одинаковым набором вершин. V1(G) и V2(G), так что каждое ребро e ребра E(G) имеет один конец в V1(G), а другой конец в V2(G) (G). Двудольность G относится к разбиению V1 U V2 = V.
Размеченный или взвешенный граф — это граф, каждое ребро которого имеет значение или вес, выражающий затраты на пересечение этого ребра.
Граф связан, если существует путь, соединяющий одну вершину структуры данных графа с любой другой вершиной.
Когда нет ребра, соединяющего вершины, нулевой граф называется несвязным графом.
Граф называется циклическим, если он имеет хотя бы один цикл графа.
Граф называется ациклическим, если он не содержит циклов.
Это тип структуры данных графа с направленными ребрами, но без циклов, также называемый DAG. Полная форма DAG — ориентированный ациклический граф. Поскольку он направляет вершины и поддерживает определенные данные, он изображает ребра с упорядоченной парой вершин.
Подграф — это набор вершин и ребер одного графа, которые являются подмножествами другого.
Ниже приведены наиболее частые операции, которые можно выполнять со структурами данных:

Связанное обучение: Сложность времени и пространства в структуре данных
Существуют три ситуации, которые обычно используются для относительного сравнения времени выполнения различных структур данных.


Одна из самых важных вещей, которую нужно усвоить, когда ищешь ответ на свой вопрос — что такое структура данных? Чем полезна структура данных?
Структуры данных предлагают множество преимуществ для процессов, связанных с ИТ, особенно по мере того, как приложения становятся все более сложными, а объем существующих данных продолжает расти. Вот несколько причин, по которым структуры данных необходимы.
 Как только вы реализуете данную структуру данных, ее можно использовать где угодно. Нет необходимости создавать новую структуру. Эта функция экономит время и ресурсы.
Как только вы реализуете данную структуру данных, ее можно использовать где угодно. Нет необходимости создавать новую структуру. Эта функция экономит время и ресурсы. Структуры данных имеют множество применений, например:
Структуры данных способствуют эффективному сохранению данных, например, указание коллекций атрибутов и соответствующих структур, используемых в системах управления базами данных для хранения записей.

Организованная информация, определяемая структурами данных, может совместно использоваться приложениями, например, пакетами TCP/IP.
Структуры данных, такие как связанные списки, могут позволить основным ресурсам и службам операционной системы выполнять такие функции, как управление файловыми каталогами, выделение памяти и планирование обработки очередей.
Приложения для работы с большими данными полагаются на структуры данных для управления и распределения хранилища данных во многих распределенных хранилищах. Эта функция гарантирует масштабируемость и высокую производительность.


Ускорьте свою карьеру в науке о данных с помощью уникальной 6-месячной программы Simplilearn Data Science Job Guarantee и получите работу своей мечты в ведущих компаниях в течение 180 дней после выпуска.
Данные — это топливо, которое питает современные двигатели коммерции, и ученые, работающие с данными, пользуются большим спросом. С 2012 года спрос на специалистов по данным вырос на 650%, и эта тенденция не ослабевает. Профессия специалиста по данным продолжает оставаться одной из самых популярных профессий в области ИТ сегодня, и теперь вы можете присоединиться к этому захватывающему призванию.
Simplilearn имеет профессиональную сертификационную программу по курсу Data Science, которая обучает вас всему, что вам нужно, чтобы обеспечить идеальную должность специалиста по данным. Программа учебного курса по науке о данных идеально подходит для всех ИТ-специалистов, занимающихся критически важными темами, такими как R, программирование на Python, алгоритмы машинного обучения, концепции НЛП и визуализация данных с помощью Tableau. Эти и другие темы очень подробно рассматриваются в нашей интерактивной модели обучения, включающей живые занятия специалистов-практиков со всего мира, практические лаборатории, хакатоны IBM и отраслевые проекты.
Программа учебного курса по науке о данных идеально подходит для всех ИТ-специалистов, занимающихся критически важными темами, такими как R, программирование на Python, алгоритмы машинного обучения, концепции НЛП и визуализация данных с помощью Tableau. Эти и другие темы очень подробно рассматриваются в нашей интерактивной модели обучения, включающей живые занятия специалистов-практиков со всего мира, практические лаборатории, хакатоны IBM и отраслевые проекты.
Этот учебный курс, проводимый в сотрудничестве с Университетом Пердью и IBM, является программой № 1 для аспирантов в области наук о данных по версии ET. Вы даже получаете мастер-классы от преподавателей Purdue и экспертов IBM, а также сеансы «Спросите меня о чем угодно» от IBM.
Согласно данным компании Indeed, американские специалисты по данным зарабатывают в среднем 120 334 доллара США в год. По данным Payscale, специалисты по данным в Индии зарабатывают в среднем 822 895 фунтов стерлингов в год.
Воспользуйтесь преимуществами курсов Simplilearn и начните путь, обещающий долгую и успешную карьеру. Зарегистрироваться Сегодня!
Зарегистрироваться Сегодня!
Структуры данных — это программный способ хранения данных, позволяющий эффективно использовать данные. Почти каждое корпоративное приложение так или иначе использует различные типы структур данных. Этот учебник даст вам отличное представление о структурах данных, необходимых для понимания сложности приложений корпоративного уровня и необходимости алгоритмов и структур данных.
Поскольку приложения становятся все более сложными и объемными, в настоящее время приложения сталкиваются с тремя распространенными проблемами.
Поиск данных — Рассмотрим запас в 1 миллион (10 6 ) единиц товара в магазине. Если приложение должно искать элемент, оно должно каждый раз искать элемент в 1 миллионе (10 6 ) элементов, что замедляет поиск. По мере роста данных поиск будет замедляться.
Скорость процессора — Скорость процессора, хотя и очень высокая, падает ограниченно, если данные вырастают до миллиарда записей.
Множественные запросы — Поскольку тысячи пользователей могут одновременно искать данные на веб-сервере, даже быстрый сервер выходит из строя при поиске данных.
Для решения вышеуказанных проблем на помощь приходят структуры данных. Данные могут быть организованы в структуру данных таким образом, что может не потребоваться поиск всех элементов, а поиск необходимых данных может осуществляться практически мгновенно.
Алгоритм — это пошаговая процедура, которая определяет набор инструкций, которые необходимо выполнить в определенном порядке для получения желаемого результата. Алгоритмы обычно создаются независимо от базовых языков, т. е. алгоритм может быть реализован более чем на одном языке программирования.
С точки зрения структуры данных, ниже приведены некоторые важные категории алгоритмов —
Поиск — Алгоритм поиска элемента в структуре данных.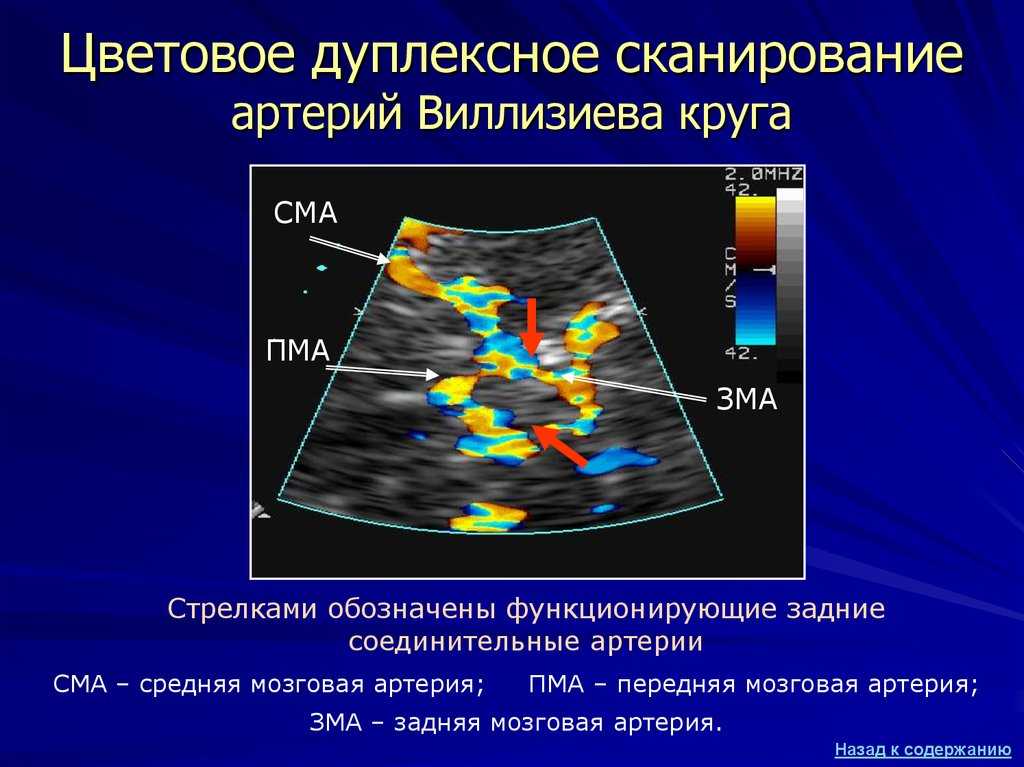
Сортировка — Алгоритм сортировки элементов в определенном порядке.
Вставка — Алгоритм вставки элемента в структуру данных.
Обновление — Алгоритм обновления существующего элемента в структуре данных.
Удалить — Алгоритм удаления существующего элемента из структуры данных.
Следующие компьютерные проблемы можно решить с помощью структур данных —
Этот учебник предназначен для выпускников компьютерных наук, а также для профессионалов в области программного обеспечения, которые хотят изучить структуры данных и программирование алгоритмов простыми и легкими шагами.
После прохождения этого урока вы перейдете на средний уровень мастерства, откуда вы сможете перейти на более высокий уровень мастерства.